POPULAR COURSES
Master Programs





Table of contents:
|
1. Key Points at a Glance |
|
2. What is Apache Hadoop in Big Data? |
|
3. How is Hadoop Used in Data Science? |
|
4. Apache Hadoop Architecture Explained |
|
5. Apache Hadoop in Cloud Computing
|
|
6. Apache Hadoop Tools You Should Know
|
|
7. Hadoop vs Traditional Data Systems |
|
8. Benefits of Learning Hadoop for Data Science |
|
9. Practical Tips to Get Started with Hadoop |
|
10. Example Use Case: Retail Analytics |
|
11. Final Thoughts |
|
12. FAQs |
Ever wondered how companies like Netflix or Amazon process massive amounts of data in real time without slowing down? The answer often lies in powerful big data frameworks like Hadoop, working alongside tools such as Apache Spark for data science to analyse and process data at lightning speed.
If you are planning to enrol in a Data science course in Bangalore, understanding Hadoop is a critical step toward building a strong foundation in big data.
In today’s digital landscape, over 2.5 quintillion bytes of data are generated every day, from social media interactions to IoT devices and business transactions. Traditional databases simply cannot handle this scale efficiently. That’s where Hadoop comes in, offering a scalable, cost-effective, and reliable solution for managing big data. But what makes Hadoop so powerful, and why is it still a must-have skill for aspiring data scientists? Let’s understand.
Key Points at a Glance
-
Hadoop is a distributed computing framework designed for large-scale data processing
-
It enables the storage and processing of structured, semi-structured, and unstructured data
-
Understanding Apache Hadoop architecture helps you grasp real-world data systems
-
Hadoop plays a vital role in data science pipelines and machine learning workflows
-
It integrates with cloud platforms, making Apache Hadoop in cloud computing highly relevant
-
The Hadoop ecosystem includes tools like Hive, Pig, and Spark, which are important Apache Hadoop tools
-
Learning Hadoop opens doors to roles in data science, data engineering, and cloud computing
What is Apache Hadoop in Big Data?
To truly understand Hadoop, let’s break it down in a simple way.
Apache Hadoop is an open-source framework that allows organisations to store and process massive volumes of data across clusters of computers. Instead of relying on a single machine, Hadoop distributes data and computation tasks across multiple nodes.
Key Characteristics of Hadoop:
-
Distributed Storage: Data is stored across multiple machines
-
Parallel Processing: Tasks are executed simultaneously
-
Fault Tolerance: Data is automatically replicated to prevent loss
-
Scalability: Easily add more nodes as data grows
When people ask, “What is Apache Hadoop in big data?”, think of it as a system that makes handling “big data” practical, efficient, and scalable.
How is Hadoop Used in Data Science?

Now let’s address the big question: how is Hadoop used in data science?
Data science involves extracting insights from large datasets, and Hadoop plays a central role in enabling this process.
Key Applications in Data Science:
1. Data Collection & Storage
Hadoop’s HDFS stores massive datasets from multiple sources like social media, sensors, and logs.
2. Data Cleaning & Preparation
Raw data is often messy. Hadoop helps preprocess and organise data for analysis.
3. Data Processing
Using MapReduce and Spark, Hadoop processes large datasets in parallel, reducing computation time drastically.
4. Machine Learning Integration
Hadoop integrates with ML libraries to train models on large datasets.
Real-World Examples:
-
E-commerce: Personalised recommendations based on browsing history
-
Healthcare: Predictive analytics for disease diagnosis
-
Finance: Fraud detection using transaction patterns
-
Telecom: Customer churn prediction
Without Hadoop, handling such massive datasets would be nearly impossible.
Apache Hadoop Architecture Explained
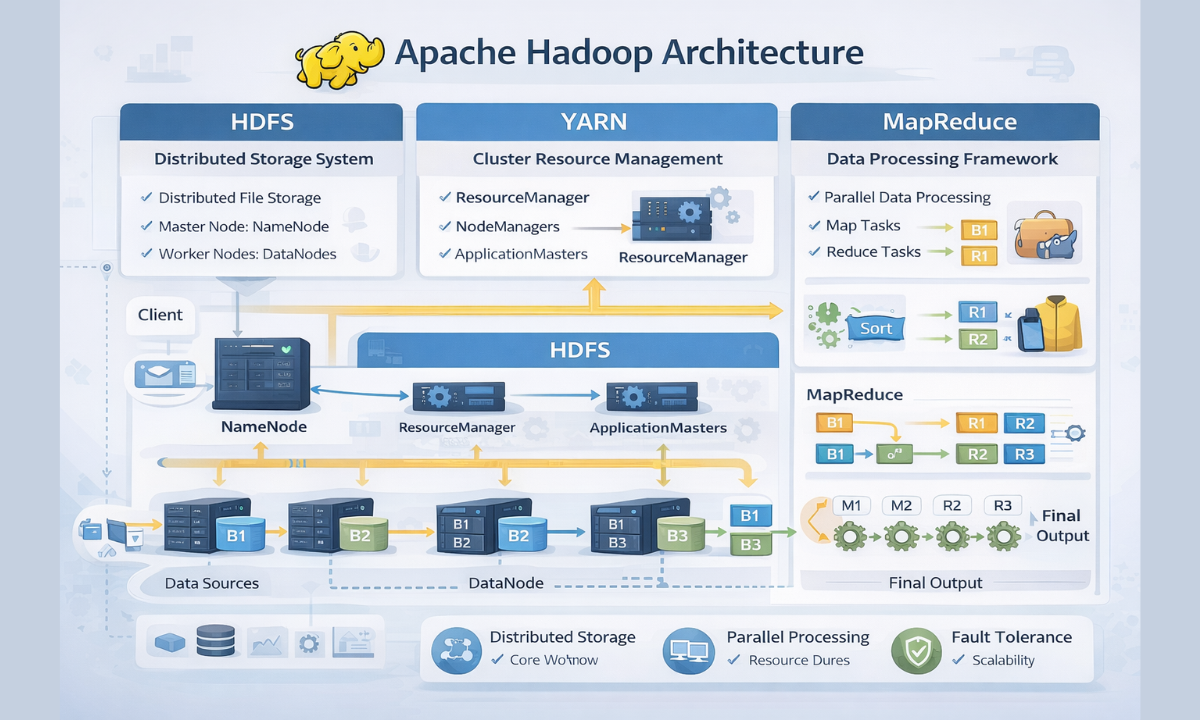
Understanding Apache Hadoop architecture is essential for anyone entering the big data space.
Here’s a deeper look at its components:
|
Component |
Function |
Why It Matters |
|
HDFS |
Distributed storage system |
Ensures data reliability and scalability |
|
MapReduce |
Data processing model |
Enables parallel computation |
|
YARN |
Resource management |
Optimises performance and job scheduling |
|
NameNode |
Master node |
Keeps track of data locations |
|
DataNode |
Worker nodes |
Store and process actual data |
Step-by-Step Workflow:
-
Data is divided into smaller blocks (typically 128MB each)
-
Blocks are distributed across multiple DataNodes
-
MapReduce processes data in parallel
-
Results are aggregated and returned
This architecture ensures high performance, reliability, and scalability, even for petabytes of data.
Apache Hadoop in Cloud Computing
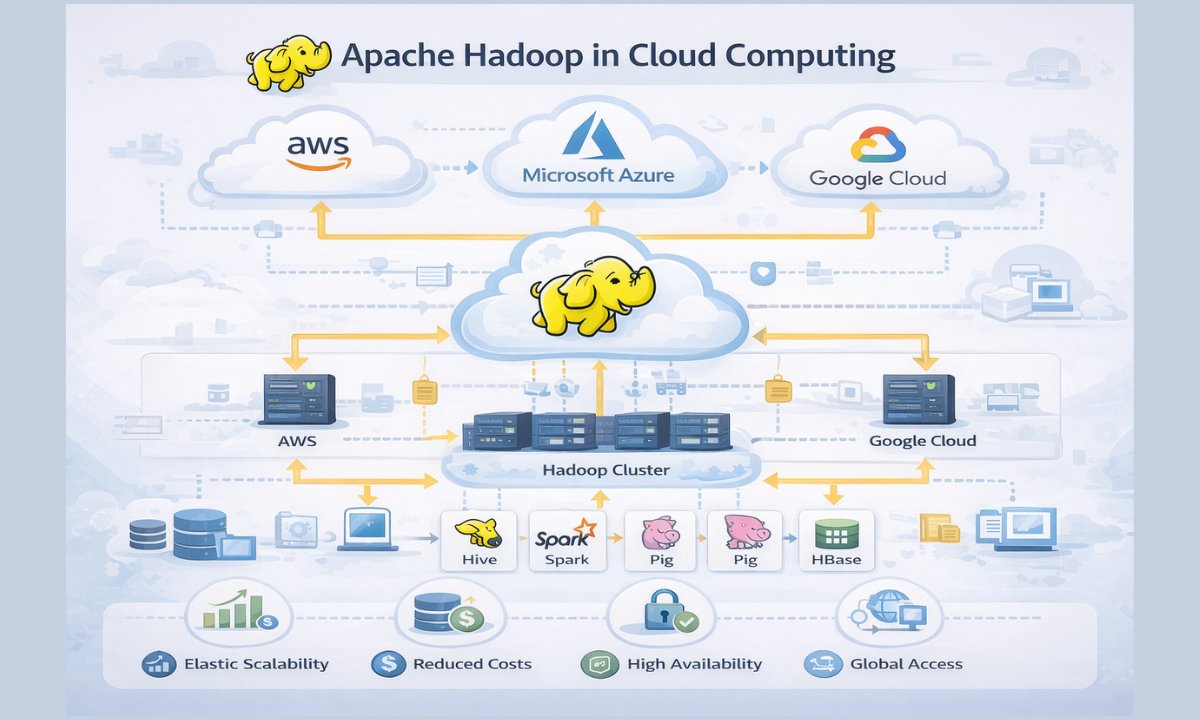
As organisations shift toward cloud-based solutions, Apache Hadoop in cloud computing has gained immense importance.
Why Combine Hadoop with Cloud?
-
Elastic Scalability: Instantly scale resources based on demand
-
Reduced Infrastructure Costs: No need for physical hardware
-
High Availability: Cloud platforms ensure minimal downtime
-
Global Access: Teams can access data from anywhere
Popular Cloud Platforms Supporting Hadoop:
-
AWS (Amazon EMR)
-
Microsoft Azure (HDInsight)
-
Google Cloud Dataproc
This combination allows businesses to process big data faster, cheaper, and more efficiently.
Apache Hadoop Tools You Should Know
Hadoop is not just a single framework; it’s an entire ecosystem of tools designed for different tasks.
Here’s a more detailed look at essential Apache Hadoop tools:
|
Tool |
Purpose |
Example Use |
|
Hive |
SQL-like querying |
Data analysis using familiar SQL syntax |
|
Pig |
Data scripting |
Simplifies complex data transformations |
|
HBase |
NoSQL database |
Real-time data access |
|
Sqoop |
Data transfer |
Import/export data between Hadoop & databases |
|
Flume |
Data ingestion |
Collect log data from multiple sources |
|
Spark |
Fast processing engine |
Real-time analytics and ML |
Why Spark is a Game-Changer?
While Hadoop’s MapReduce is powerful, Spark takes it further by processing data in-memory, making it significantly faster.
That’s why Apache Spark for data science is widely used for:
-
Real-time analytics
-
Machine learning
-
Streaming data processing
Hadoop vs Traditional Data Systems
Understanding the difference helps you appreciate Hadoop’s value.
|
Feature |
Traditional Systems |
Hadoop |
|
Scalability |
Limited |
Highly scalable |
|
Cost |
Expensive hardware |
Cost-effective clusters |
|
Data Handling |
Structured only |
All data types |
|
Processing Speed |
Slower |
Faster with parallel processing |
|
Fault Tolerance |
Low |
High |
Hadoop’s flexibility and efficiency make it the backbone of modern data systems.
Benefits of Learning Hadoop for Data Science
Learning Hadoop can significantly boost your career.
Top Benefits:
1. High-Demand Skills
Big data professionals are among the most sought-after globally.
2. Attractive Salaries
Data engineers and Hadoop experts often earn 20–40% higher salaries.
3. Cross-Industry Opportunities
From healthcare to fintech, Hadoop skills are universally valuable.
4. Strong Career Foundation
Hadoop knowledge supports advanced learning in AI, ML, and cloud computing.
Practical Tips to Get Started with Hadoop
Starting Hadoop may seem overwhelming, but breaking it into steps helps.
Beginner Roadmap:
-
Understand data structures and databases
-
Explore Hadoop ecosystem tools
-
Practice with real-world datasets
-
Build projects like log analysis or recommendation systems
Bonus Tip:
Join a Cloud computing course in Bangalore to understand how Hadoop integrates with modern cloud platforms.
Example Use Case: Retail Analytics
Let’s look at a practical scenario.
A retail company uses Hadoop to:
-
Store millions of customer transactions
-
Analyze buying behavior
-
Predict future purchases
-
Offer personalized discounts
Result: Improved customer engagement and increased revenue.
Final Thoughts
Apache Hadoop continues to be a cornerstone of big data and data science, enabling organisations to process massive datasets efficiently. Whether you are building predictive models, analysing user behaviour, or working with cloud platforms, Hadoop skills give you a strong competitive edge.
If you are considering a Data science course in Bangalore, ensure it includes hands-on training in Hadoop and Spark. At Apponix, a trusted training institute in Bangalore, you can gain practical exposure to real-world projects, industry tools, and cloud integration, helping you become job-ready faster.
FAQs
1. Is Hadoop still relevant in 2026?
Yes, Hadoop continues to be highly relevant in 2026, especially for distributed data storage and large-scale batch processing. While Apache Spark has gained popularity for faster, in-memory computation, Hadoop remains the backbone for handling massive datasets. Many organisations still rely on Hadoop ecosystems for scalability, reliability, and cost-effective big data infrastructure.
2. Do I need coding skills to learn Hadoop?
Basic coding skills are helpful when learning Hadoop, particularly in languages like Python or Java. However, beginners can still get started using user-friendly tools like Hive and Pig, which require minimal programming knowledge. As you progress, having coding expertise will make it easier to work with advanced data processing and real-world Hadoop applications.
3. How long does it take to learn Hadoop?
The time required to learn Hadoop depends on your background and learning pace. Generally, beginners can understand the core concepts within 4–8 weeks with consistent practice. However, mastering the Hadoop ecosystem, including tools like Spark and Hive, may take a few months of hands-on experience and working on real-world data projects.

Apponix Academy
Apponix Academy