POPULAR COURSES
Master Programs





Table of contents:
|
1. Key Takeaways |
|
2. What is Big Data in Data Science? |
|
3. Why Big Data is Important |
|
4. Big Data Architecture Explained |
|
5. Classification of Big Data |
|
6. Top Big Data Tools Used in Data Science |
|
7. Applications of Big Data in Data Science |
|
8. How Big Data Works in Data Science |
|
9. Skills You Need to Work with Big Data |
|
10. Common Challenges in Big Data |
|
11. Tips to Get Started with Big Data |
|
12. Final Thoughts |
|
13. FAQs |
Have you ever wondered how companies like Netflix, Amazon, or Google predict exactly what you want before you even search for it? The answer lies in how they leverage big data in data science to uncover patterns, trends, and insights at scale. Today, businesses are generating massive volumes of data every second, and those who know how to use it gain a serious competitive edge.
If you're exploring a Data science course in Bangalore, understanding big data is no longer optional; it is a core skill that defines success in this field. But what exactly is big data, how does it work, and why should you care? Let’s break it down in a way that’s simple, practical, and impossible to ignore.
Key Takeaways
-
Big data refers to extremely large datasets that cannot be handled using traditional tools
-
It plays a critical role in modern data science workflows
-
Understanding big data architecture is essential for processing large-scale data
-
There are different types and classifications of big data based on structure
-
Big data tools like Hadoop and Spark are widely used in the industry
-
Businesses rely on big data for decision-making, automation, and personalisation
-
Learning big data boosts career opportunities in data science
What is Big Data in Data Science?

Let’s start with the basics: what is big data in data science?
Big data refers to massive volumes of structured, semi-structured, and unstructured data that are generated at high speed from multiple sources. In data science, this data is analysed to extract meaningful insights and support decision-making.
Big data is often defined by the 3 Vs:
-
Volume – Huge amounts of data (terabytes to petabytes)
-
Velocity – Data generated in real-time or near real-time
-
Variety – Different formats like text, videos, images, logs
Today, experts also include Veracity (data quality) and Value (usefulness), making it the 5 Vs.
Why Big Data is Important
Still wondering why big data is important? The answer is simple: data drives everything.
Here’s why businesses cannot ignore it:
-
Better Decision Making: Companies use real-time analytics to make faster and smarter decisions
-
Personalisation: Platforms recommend products, movies, and content based on your behaviour
-
Cost Efficiency: Big data tools reduce storage and processing costs
-
Risk Management: Detect fraud, predict failures, and improve security
-
Innovation: Enables Artificial Intelligence(AI), machine learning, and automation
Stat Insight: According to industry reports, over 90% of the world’s data has been created in the last few years, highlighting the explosive growth of big data.
Big Data Architecture Explained
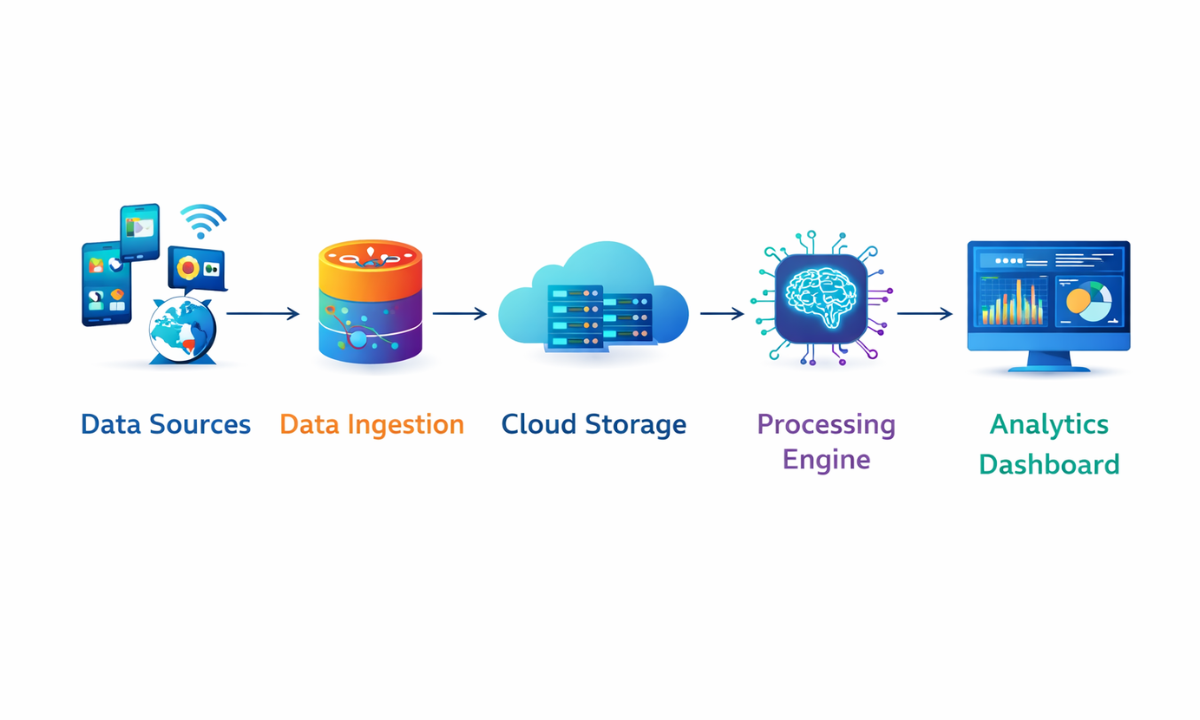
To handle such massive data efficiently, organisations rely on a structured system called big data architecture.
Key Components of Big Data Architecture
|
Component |
Description |
|
Data Sources |
Social media, sensors, transactions, apps |
|
Data Ingestion |
Collecting data using tools like Kafka |
|
Storage |
Data lakes, HDFS, cloud storage |
|
Processing |
Batch (Hadoop) or real-time (Spark) |
|
Analytics |
Data analysis using ML and AI |
|
Visualization |
Dashboards and reporting tools |
This architecture ensures smooth data flow from collection to insights.
Classification of Big Data
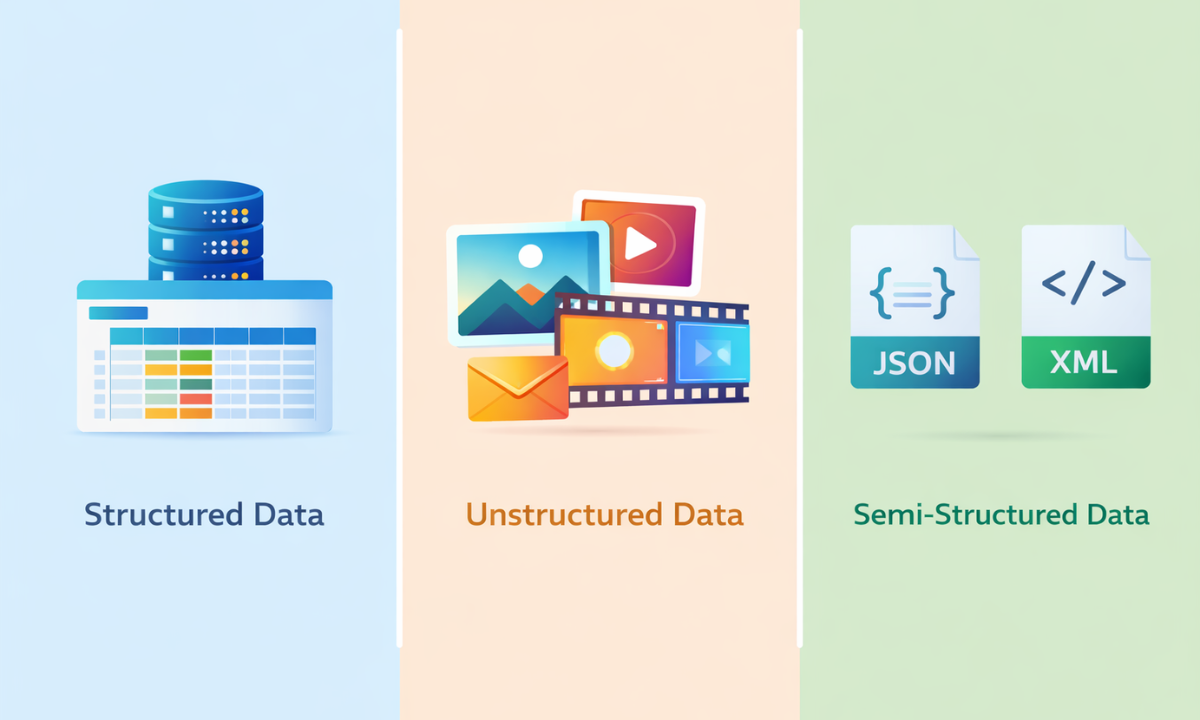
Understanding the classification of big data helps you know how data is stored, processed, and analysed in real-world scenarios. Each type requires different tools and techniques, which is why this distinction is crucial in data science.
1. Structured Data
-
Highly organised and easy to store
-
Stored in databases using rows and columns
-
Can be processed using traditional tools like SQL
Examples:
-
Excel sheets
-
Relational databases (MySQL, PostgreSQL)
Additional Insight: Structured data is the easiest to analyse because it follows a fixed schema, making querying fast and efficient.
2. Unstructured Data
-
No predefined format or structure
-
Difficult to store and analyse using traditional systems
-
Requires advanced tools like Hadoop or AI-based models
Examples:
-
Videos and images
-
Emails and chat messages
-
Social media posts
Additional Insight: Unstructured data contains valuable insights like customer sentiment, but extracting meaning requires technologies like Natural Language Processing (NLP) and machine learning.
3. Semi-Structured Data
-
Partially organised, but does not follow strict table formats
-
Uses tags, keys, or markers to define data elements
-
More flexible than structured data
Examples:
-
JSON files
-
XML files
-
NoSQL databases
Additional Insight: Semi-structured data acts as a bridge between structured and unstructured data, offering flexibility while still being machine-readable.
Real-World Insight: Around 80% of global data is unstructured, which is why modern big data tools and frameworks are designed to handle complex and diverse data formats efficiently.
Top Big Data Tools Used in Data Science

To work with big data, professionals rely on powerful tools.
Most Popular Big Data Tools
-
Hadoop – Distributed storage and batch processing
-
Apache Spark – Fast, in-memory data processing
-
Kafka – Real-time data streaming
-
Hive – SQL-like querying on big data
-
NoSQL Databases – MongoDB, Cassandra
Quick Comparison
|
Tool |
Best For |
Speed |
|
Hadoop |
Batch processing |
Moderate |
|
Spark |
Real-time analytics |
Very fast |
|
Kafka |
Streaming data |
High |
|
Hive |
Querying large datasets |
Moderate |
Tip: Beginners often start with Python and Spark for practical learning.
Applications of Big Data in Data Science

Big data is not just a theory; it powers real-world solutions across industries by helping organisations make faster decisions, improve efficiency, and deliver better user experiences. Its ability to process massive datasets in real time makes it one of the most valuable assets in modern data science.
1. Healthcare
-
Predict diseases at an early stage
-
Analyse patient records and medical history
-
Improve treatment plans and hospital efficiency
Example: Hospitals use big data to monitor patient vitals in real time and detect health risks before they become critical.
2. E-commerce
-
Deliver personalised product recommendations
-
Analyse customer behaviour and buying patterns
-
Improve inventory and supply chain management
Example: Online shopping platforms suggest products based on your browsing history, increasing customer satisfaction and sales.
3. Banking & Finance
-
Detect fraudulent transactions instantly
-
Perform risk assessment for loans and investments
-
Support algorithmic trading and market predictions
Example: Banks use real-time transaction monitoring to flag suspicious activities and prevent fraud.
4. Marketing
-
Create highly targeted advertising campaigns
-
Segment customers based on preferences and habits
-
Measure campaign performance and ROI
Example: Brands analyse website clicks, social media interactions, and purchase history to run smarter campaigns.
5. Smart Cities
-
Manage traffic flow and reduce congestion
-
Optimise energy and water usage
-
Improve public safety with surveillance analytics
Example: Smart traffic systems use live sensor data to adjust signals and reduce travel time.
Industry Insight: A well-known example is how Netflix uses big data to recommend personalised content, helping improve user retention and saving billions in customer lifetime value.
How Big Data Works in Data Science
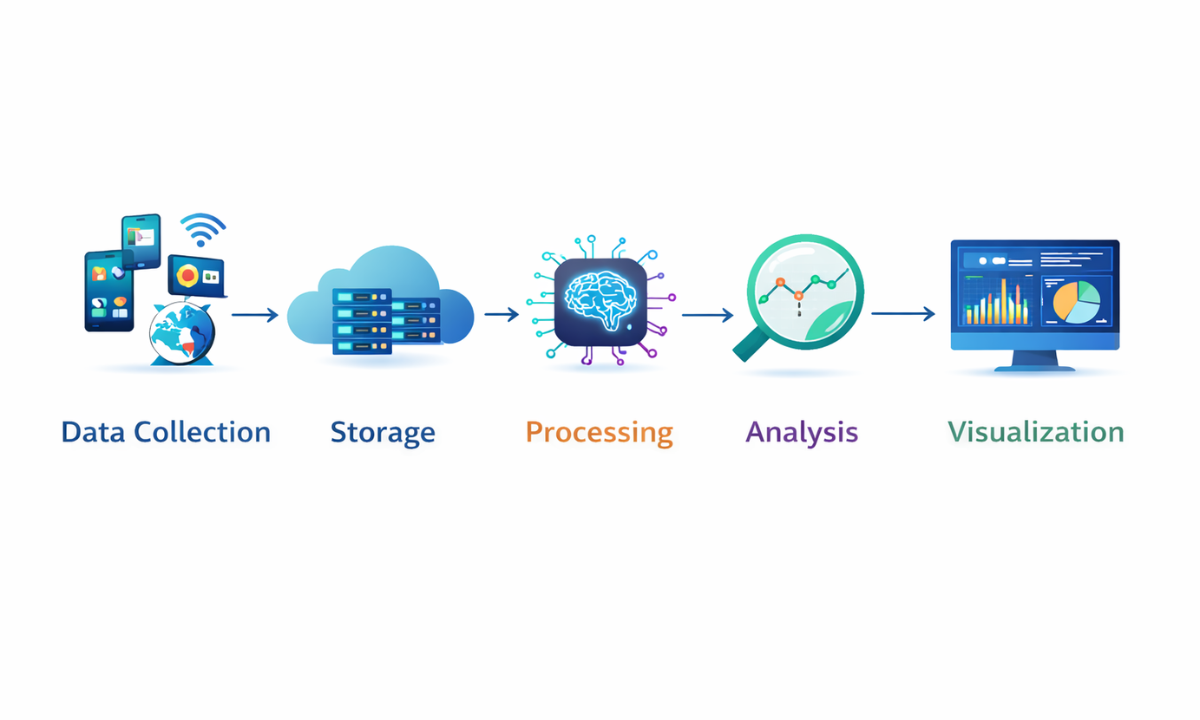
Understanding the workflow makes things clearer. In data science, big data follows a step-by-step process that turns raw information into meaningful insights businesses can act on.
1. Data Collection
Raw data is gathered from multiple sources such as websites, mobile apps, sensors, social media, and business systems. The goal is to collect relevant information continuously without losing speed or accuracy.
2. Data Storage
Once collected, the data is stored in scalable systems like cloud platforms, data lakes, or distributed databases. These systems are designed to handle huge volumes of data securely and efficiently.
3. Data Processing
At the data processing stage, the raw data is cleaned, filtered, and organised to remove errors or duplicates. This step ensures the data is reliable and ready for meaningful analysis.
4. Data Analysis
Data scientists use algorithms, machine learning models, and statistical methods to identify patterns, trends, and hidden insights. This is where businesses uncover opportunities and solve problems.
5. Data Visualisation
The final insights are presented through dashboards, charts, and reports for easy understanding. Clear data visualisation helps teams make faster and more confident decisions.
This end-to-end pipeline is the backbone of modern data science projects, helping organisations turn complex data into actionable results.
Skills You Need to Work with Big Data
To build a career in this domain, focus on:
-
Programming (Python, Java, Scala)
-
Data handling tools (Hadoop, Spark)
-
SQL and NoSQL databases
-
Data visualisation tools (Tableau, Power BI)
-
Machine learning basics
Pro Tip: Hands-on projects matter more than theory.
Common Challenges in Big Data
Big data is powerful, but not easy.
Major Challenges:
-
Managing huge volumes of data
-
Ensuring data quality and accuracy
-
Security and privacy concerns
-
High infrastructure costs
-
Lack of skilled professionals
This is why structured learning is important.
Tips to Get Started with Big Data
If you are serious about learning:
-
Start with Python and SQL basics
-
Learn data visualisation early
-
Practice real-world datasets
-
Work on mini-projects.
-
Join a practical training programme.
Consistency beats complexity here.
Final Thoughts
Big data is not just a buzzword; it is the backbone of modern data science. From powering AI systems to transforming industries, its impact is massive and growing every day.
If you are planning to build a career in this space, enrolling in a Data science course in Bangalore can give you structured learning, hands-on experience, and industry exposure. At Apponix, a training institute in Bangalore, learners gain practical skills that help them confidently step into real-world data roles.
The future belongs to those who understand data, so the real question is, are you ready to be one of them?
FAQs
1. Is big data part of data science?
Yes, big data is a fundamental part of data science because it enables professionals to work with massive and complex datasets that traditional tools cannot handle. Data science relies on big data technologies to collect, process, and analyse information at scale, helping organisations uncover patterns, make predictions, and drive smarter business decisions.
2. Do I need coding for big data?
Yes, coding is essential for working with big data effectively. Programming languages like Python, Java, or Scala are commonly used to process, analyse, and manage large datasets. Coding helps automate tasks, build data pipelines, and work with tools like Hadoop and Spark, making it a crucial skill for anyone entering this field.
3. Is big data a good career?
Big data is an excellent career choice due to its high demand, competitive salaries, and wide range of opportunities across industries. As organisations continue to generate massive amounts of data, skilled professionals are needed to analyse and interpret it. Roles in big data and data science also offer strong career growth and global job prospects.
4. Which tool should beginners learn first?
Beginners should start with Python because it is easy to learn, versatile, and widely used in data science and big data projects. Once comfortable, they can move on to tools like Apache Spark for faster data processing or Hadoop for distributed storage. Building a strong foundation step by step makes learning more effective and practical.

Apponix Academy
Apponix Academy