POPULAR COURSES
Master Programs





Table of contents:
|
1. Foundation & Readability (Writing Production-Grade SQL)
|
|
2. Visualizing the Difference: Legacy vs. Enterprise SQL |
|
3. Structural Aggregation & Summarization
|
|
4. Computational Performance & Advanced Optimization
|
|
5. Enterprise Governance & Versioning
|
|
6. Why Choose Apponix Academy for Data Analytics? |
|
7. Conclusion |
Let’s skip the basics. If you are reading this in 2026, you already know that running a blind SELECT * in production is a terrible idea.
The modern enterprise data landscape has evolved far beyond querying simple, gigabyte-sized relational tables. Today, analysts are pulling insights from terabyte-scale, columnar cloud warehouses like Snowflake, BigQuery, and Databricks.
In this high-volume environment, poorly written SQL for data analytics doesn't just slow down your dashboard; it actively burns through your company’s cloud compute budget.
As an instructor leading a premium Data analytics course in Bangalore, I see the same problem repeatedly: aspiring professionals master the syntax, but they fail at the architecture. Despite the recent explosion of AI automation and drag-and-drop BI tools, SQL remains the undisputed, 50-year-old backbone of global tech operations.
Writing a query that simply 'returns the right answer' is no longer enough. You are now expected to write code that is cost-efficient, structurally scalable, and instantly readable by your peers in a massive Git codebase.
Whether you are debugging a broken reporting pipeline, migrating legacy data, or building a fresh enterprise dashboard, it is time to start treating your queries like real, production-grade software.
Here are the top 10 advanced best practices that separate amateur query-writers from elite data professionals.
Foundation & Readability (Writing Production-Grade SQL)
Before we tackle complex mathematical functions or join algorithms, we have to fix the foundation. The biggest shock for junior analysts entering the corporate world is realizing that writing a query that gets the right answer is only 20% of the job.
Whether you're working on a small SQL project or a large-scale enterprise analytics initiative, your SQL code will be committed to version control (like Git), reviewed by senior data engineers, and scheduled to run daily in automated pipelines.
If your code is messy, expensive to execute, or impossible to read, it will not pass code review. Here are the first three foundational habits you must adopt to write production-ready SQL.
1. Explicit Column Selection Over Wildcards

In academic environments running traditional row-based databases (like MySQL or PostgreSQL), typing SELECT * is treated as a mild formatting sin. In modern, terabyte-scale columnar data warehouses (like Snowflake or Google BigQuery), it is a massive financial leak.
Columnar databases physically store data by columns, not rows. They also bill your company based on the total volume of data scanned during execution. If an enterprise "Sales" table has 150 columns and you only need revenue and date, using SELECT * forces the warehouse to scan all 150 columns. You have just increased the compute cost of that query by a massive margin for zero analytical value.
-
The Rule: Always type out the exact columns you need. It reduces cloud spend, minimizes network payload, and immediately tells the next engineer exactly what data this query relies on.
2. Enforcing Semantic Clarity via Layout

SQL is read significantly more often than it is written. When a data pipeline breaks at 3:00 AM, the engineer debugging your code needs to understand it instantly. Do not write monolithic, unformatted walls of text.
Adopt strict formatting rules: capitalize all SQL keywords (SELECT, FROM, WHERE), use consistent indentation, and most importantly, utilize descriptive aliases. Never alias a table or calculation as simply a, b, or t1. If you are joining a table containing user data, alias it as active_users or q3_revenue. When an analyst reads active_users.account_id, the logic is instantly clear; when they read a.id, they have to reverse-engineer your entire script.
3. Replace Onion-Style Subqueries with CTEs
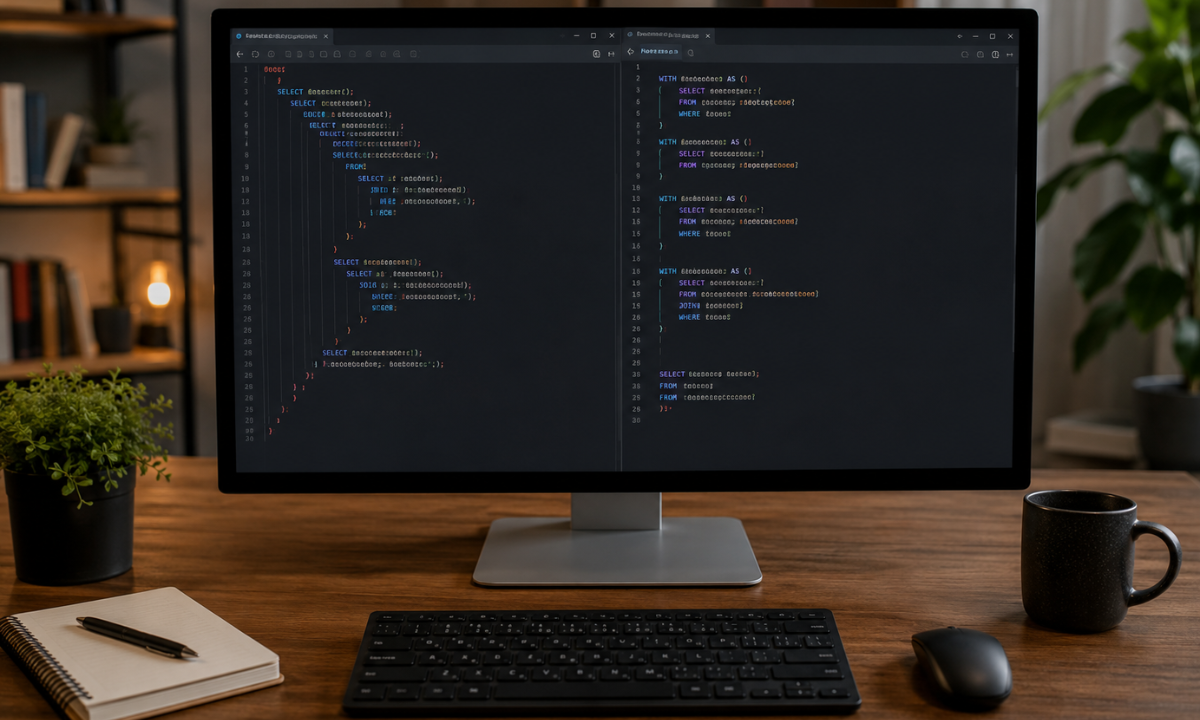
A nested subquery occurs when you place a query inside another query's FROM or WHERE clause. While technically functional, nesting creates an "onion" structure. To understand what the query is doing, a reviewer has to start reading from the innermost core of the code and peel it backwards, jumping up and down the script.
By 2026, Common Table Expressions (CTEs) utilizing the WITH clause will be the absolute industry standard. CTEs allow you to define temporary result sets sequentially, from top to bottom. This transforms a chaotic, nested nightmare into a series of readable, logical building blocks that tell a clear, chronological story of how the data is being transformed.
Visualizing the Difference: Legacy vs. Enterprise SQL
To illustrate how these three foundational practices completely transform your code, look at this exact data transformation task written two different ways:
The Amateur Approach (The "Onion" Subquery): It uses SELECT *, terrible aliases, lowercase keywords, and requires reading from the inside out.
|
SQL |
|
select u.name, s.total_spent from users u join ( select user_id, sum(amount) as total_spent from sales where year = 2026 group by user_id ) s on u.id = s.user_id; |
The Professional Approach (Production-Grade): It uses sequential CTEs, explicit column selection, capitalized keywords, and descriptive aliases.
|
SQL |
|
WITH regional_sales_2026 AS ( SELECT user_id, SUM(transaction_amount) AS total_annual_spend FROM raw_data.enterprise_sales WHERE transaction_year = 2026 GROUP BY user_id ), active_users AS ( SELECT account_id, full_name, region FROM raw_data.global_users WHERE account_status = 'Active' ) SELECT active_users.full_name, active_users.region, regional_sales_2026.total_annual_spend FROM active_users INNER JOIN regional_sales_2026 ON active_users.account_id = regional_sales_2026.user_id; |
Notice the difference? The second query reads like an instruction manual. It defines the sales data, defines the user data, and then cleanly merges them at the end. This is the exact caliber of coding we train our students to produce at Apponix Academy before they ever sit for a technical interview.
Structural Aggregation & Summarization
Once your query foundation is clean and readable, you have to tackle the heavy lifting: the math. In data analytics, raw row-level data is rarely presented to stakeholders.
You are expected to compress billions of transaction rows into high-level business metrics. However, aggregation is exactly where amateur analysts accidentally trigger "Out of Memory" errors or cause queries to run for hours on cloud servers.
Here is how elite data professionals handle massive data compression without breaking the warehouse.
4. Streamlining Pipelines with Precise Aggregate Functions

When junior analysts are asked to find the total sales per region, they often misuse Aggregate functions (SUM, AVG, COUNT, MAX) by pairing them with a bloated GROUP BY clause.
If you group by 15 different columns just because they happen to be in your SELECT statement, you force the database engine to create a massive, highly complex matrix in its memory before it can even calculate the math.
-
The Rule: Aggregate early and aggregate strictly. Group your data by the absolute minimum number of dimensions required to get your math right (e.g., group by region_id only). If you need to attach descriptive labels (like region_name or regional_manager), do the heavy math first inside a CTE, and then JOIN those descriptive columns onto your aggregated results later. This dramatically reduces the memory footprint of your mathematical pipeline.
5. Single-Pass Conditional Aggregation for Data Summarization

This is perhaps the most powerful performance trick in an advanced analyst's toolkit. Let’s say your stakeholders want a dashboard showing total users, active users, and canceled users, broken down by month.
The amateur instinct is to write three separate subqueries (or three expensive LEFT JOINs) filtering for each specific status, and then stitch them together. This forces the data warehouse to scan the massive user table three separate times, instantly tripling your cloud compute cost.
The professional standard for modern Data summarization is to use "Conditional Aggregation." By placing a CASE WHEN statement inside your aggregate function, you can evaluate different conditions row-by-row during a single, highly efficient table scan.
The Amateur Approach (Expensive Multi-Scan): Forces the database to scan the table multiple times and execute heavy joins.
|
SQL |
|
SELECT a.creation_month, a.total_users, b.active_users FROM ( SELECT creation_month, COUNT(id) AS total_users FROM users GROUP BY creation_month ) a LEFT JOIN ( SELECT creation_month, COUNT(id) AS active_users FROM users WHERE status = 'Active' GROUP BY creation_month ) b ON a.creation_month = b.creation_month; |
The Professional Approach (Single-Pass Conditional Aggregation): Scans the table exactly once. Highly optimized, cheaper, and much easier to read.
|
SQL |
|
SELECT account_creation_month, COUNT(account_id) AS total_users, SUM(CASE WHEN account_status = 'Active' THEN 1 ELSE 0 END) AS active_users, SUM(CASE WHEN account_status = 'Canceled' THEN 1 ELSE 0 END) AS canceled_users FROM raw_data.global_users GROUP BY account_creation_month; |
This single technique instantly elevates your code from just working to highly optimized and production-ready. Mastering these structural efficiencies is exactly what separates the top-tier candidates during technical interviews for data engineering roles.
Computational Performance & Advanced Optimization
Writing SQL that is readable and logically sound is a great milestone, but in the corporate world, speed and cost are king. Cloud data warehouses like Snowflake bill your company based on compute time and data scanned. A query that takes 45 minutes and $50 to run every morning will quickly get flagged by data engineering teams.
To elevate your skills to a senior level, you must understand the underlying computational mechanics of the database. Here are three advanced optimization techniques that drastically reduce execution time and cloud spend.
6. Leveraging Window Functions Over Heavy Self-Joins

One of the most common analytical tasks is calculating running totals, finding month-over-month growth, or comparing a user's current transaction to their previous one.
The amateur approach is to use a Self-Join joining a massive table to itself using offset dates. This is computationally disastrous because it creates a Cartesian product effect, forcing the database to evaluate millions of row combinations, often resulting in server timeouts.
Mastering advanced sql for data analytics means completely abandoning self-joins for sequential row operations and using Window Functions instead. By utilizing functions like LEAD(), LAG(), and ROW_NUMBER() paired with an OVER (PARTITION BY ...) clause, you can compute rolling metrics and access previous rows in a single, highly efficient table scan. This technique alone will make your code run exponentially faster.
7. Precise JOIN Strategy and Filter Placement

When joining two tables containing hundreds of millions of rows, when you filter the data dictates the cost of the query.
The most common mistake junior analysts make is joining two massive, unfiltered tables together and then applying a WHERE clause at the very bottom of the script. This forces the database to hold a massive, multi-gigabyte joined dataset in its active memory, only to throw away 90% of it a millisecond later when the filter is applied.
-
The Rule: Filter as early as computationally possible. Apply your WHERE filters inside your CTEs before the join occurs. If you only need data from the "US" region for "2026", filter the raw tables down to just those records first. By the time the JOIN executes, the database is only merging a few thousand rows instead of a few billion.
8. Writing SARGable (Search-Argument-Able) Queries

This is a technical concept frequently tested in senior data analytics interviews. SARGable means that a query is written in a way that allows the database engine to utilize its internal indexes (like a book's index) to find data instantly.
If you apply a mathematical function or a date function directly to a column in your WHERE clause, you "break" the index. The database can no longer use its shortcut; it is forced to read every single row in the entire table to evaluate your function (a Full Table Scan).
-
The Rule: Never manipulate the column; manipulate the constant.
The Amateur Approach (Non-SARGable): By wrapping transaction_date in the YEAR() function, the database cannot use its date index. It must scan the entire multi-year table.
|
SQL |
|
SELECT transaction_id, revenue FROM raw_data.global_sales WHERE YEAR(transaction_date) = 2026; |
The Professional Approach (SARGable): The column is left completely alone. The database instantly uses its index to jump straight to January 1, 2026.
|
SQL |
|
SELECT transaction_id, revenue FROM raw_data.global_sales WHERE transaction_date >= '2026-01-01' AND transaction_date < '2027-01-01'; |
This single, simple syntax change can reduce a query's execution time from 15 minutes down to 3 seconds on a multi-terabyte dataset.
Enterprise Governance & Versioning
The final transition from a junior analyst to a senior data professional involves changing how you view your code. In an enterprise environment, your SQL isn’t just a personal tool to pull numbers; it is production software.
If your query feeds a dashboard that the CEO checks every morning, it cannot break, and it cannot return inaccurate data just because an upstream data pipeline changed.
To ensure your code survives in the wild, you must implement strict governance and defensive programming habits.
9. Defensive Null Handling

Real-world corporate data is messy. Upstream pipelines break, app developers change data types, and tracking pixels fail. As a result, your tables will inevitably be littered with NULL values.
The amateur mistake is treating NULL as a zero. It is not a zero; it represents an "unknown" state. If you attempt to run mathematical equations or string concatenations involving a NULL value, the entire result often becomes NULL, silently corrupting your final BI dashboards.
-
The Rule: Always code defensively using COALESCE and NULLIF.
-
Use COALESCE(column_name, 0) to explicitly force any missing financial or numerical data to default to a zero before it hits your aggregate functions.
-
Use NULLIF(denominator, 0) when calculating ratios (like conversion rates) to completely prevent the dreaded "Divide by Zero" error that will instantly crash automated pipelines.
10. Building Modular, Reusable Views (The Semantic Layer)

One of the most dangerous anti-patterns in corporate data analytics is copying and pasting the same complex, 500-line SQL query into five different BI tools (e.g., Tableau, Power BI, and a Python notebook). If the business logic changes, for example, if the company updates its definition of an Active User, you now have to hunt down and update that SQL script in five different places. If you miss one, your company loses its "Single Source of Truth."
-
The Rule: Embrace the DRY (Don't Repeat Yourself) principle. Never embed complex SQL directly into a dashboard. Instead, abstract your heavy business logic into a permanent VIEW or a Materialized View inside the data warehouse.
Your dashboards should only run simple SELECT * FROM core_metrics_view. This creates a centralized semantic layer; if the logic changes, you update the SQL in one central location, and every downstream dashboard automatically inherits the correction.
Why Choose Apponix Academy for Data Analytics?
Reading about query optimization and structural aggregation is one thing; executing it inside a live, terabyte-scale cloud environment is entirely another. You cannot learn SQL for data analytics by simply watching passive video tutorials or running queries on tiny, mock Excel datasets.
To secure a high-paying role in today's data-driven tech landscape, you need hands-on, architectural experience. As the premier Training Institute in Bangalore, Apponix Academy has engineered our Data Analytics master program to simulate real-world corporate environments.
Here is how we turn ambitious learners into hired data professionals:
-
100% Practical, Lab-Based Infrastructure: We abandon the whiteboard. From week one, you are given 24/7 access to live cloud environments. You will write queries, optimize execution plans, and build modular views on massive, complex datasets.
-
Taught by Active Data Engineers: You are not learning from academic theorists. Our instructors are senior industry professionals with over 6 years of active corporate experience. They teach you the exact optimization tricks, Git versioning standards, and pipeline architectures they use daily.
-
Guaranteed Interview Schedules: Your ultimate goal is a paycheck, and that is our benchmark for success. Through our dedicated placement cell and official hiring partners, we provide robust resume optimization, mock technical interviews, and guaranteed interview schedules.
Whether you are upskilling alongside a full-time job or are a fresh graduate, our highly flexible batch timings (ranging from 7 AM to 9 PM) ensure your education fits perfectly into your schedule.
Conclusion
The days of the simple SELECT * analyst are over. Modern businesses are drowning in data, and they desperately need technical professionals who can extract actionable insights quickly, accurately, and cost-effectively. By mastering these 10 advanced best practices from precise aggregation and SARGable filtering to defensive null handling, you elevate yourself from a basic query-writer to a strategic data architect.
Do not let your career stall on the basics. Book a free demo session with Apponix Academy today and transform your analytical skills into a lucrative, future-proof career.
Reference:
https://www.analyticsvidhya.com/blog/2020/07/8-sql-techniques-data-analysis-analytics-data-science/
https://www.sprinkledata.com/blogs/top-10-practices-for-writing-sql-queries

Apponix Academy
Apponix Academy