POPULAR COURSES
Master Programs





Table of contents:
|
1. Tokenization, Embeddings and How Translating Language into Math Works |
|
2. The Transformer Architecture Breakthrough |
|
3. The Attention Mechanism and Deciphering Context
|
|
4. The Training Pipeline and From Pre-Training to Fine-Tuning |
|
5. Why Choose Apponix Academy to Master AI Architecture? |
|
6. Conclusion |
We need to shatter a massive global illusion right now. Artificial intelligence does not "think" about your questions. It does not possess a secret digital consciousness, and it certainly does not understand human emotion.
When you ask ChatGPT to write a complex Python script or summarize a lengthy financial report, you are not conversing with a sentient entity. You are interacting with an incredibly aggressive, highly optimized statistical prediction engine. Understanding exactly how large language models work requires completely abandoning the science-fiction narrative. At its absolute core, an LLM is a massive mathematical calculator specifically designed to predict the statistical probability of the next word in a sequence.
If you say "The sky is...", the model does not picture a blue sky. It simply calculates that the token "blue" has a 98.7 percent mathematical probability of following those previous three words based on trillions of text examples.
Why is understanding this mathematical reality so critical for your career in 2026?
-
The Transition to Architecture: You can no longer impress hiring managers by simply knowing how to write a clever text prompt. You must understand the underlying math to actually fine-tune and control these models.
-
Preventing Enterprise Hallucinations: When an AI confidently invents a fake legal case, it is not lying. It is simply executing a high-probability mathematical error. Knowing how the model calculates probability is the only way to fix it.
-
The Engineering Skill Gap: Enrolling in an elite AI course in Bangalore shifts you from a passive user of these tools to an active architect capable of deploying them securely within a strict corporate environment.
We are going to completely deconstruct the architecture of these predictive engines. You will understand exactly how human language is shattered into numbers, processed through neural networks, and reassembled into coherent thought.
Tokenization, Embeddings and How Translating Language into Math Works
Computers are fundamentally incapable of reading the English alphabet. A silicon processor cannot inherently understand the emotional weight of a sentence or the subtle irony of a joke. Before any artificial intelligence can even begin to predict an answer, it must ruthlessly strip away the human element and convert your text into pure mathematical coordinates.
This translation happens in two distinct, aggressive phases: Tokenization and Vector Embeddings.
First, the system shatters your input sentence into smaller chunks called tokens. A token is not necessarily a whole word. It can be a single letter, a syllable, or a common suffix like "-ing" or "-tion." By breaking language down into these foundational Lego bricks, the algorithm can process massive volumes of text efficiently without having to memorize every single word in the human dictionary.
But chopping words into pieces is useless if the machine doesn't understand what those pieces mean in relation to one another. This is where the real mathematical heavy lifting begins.
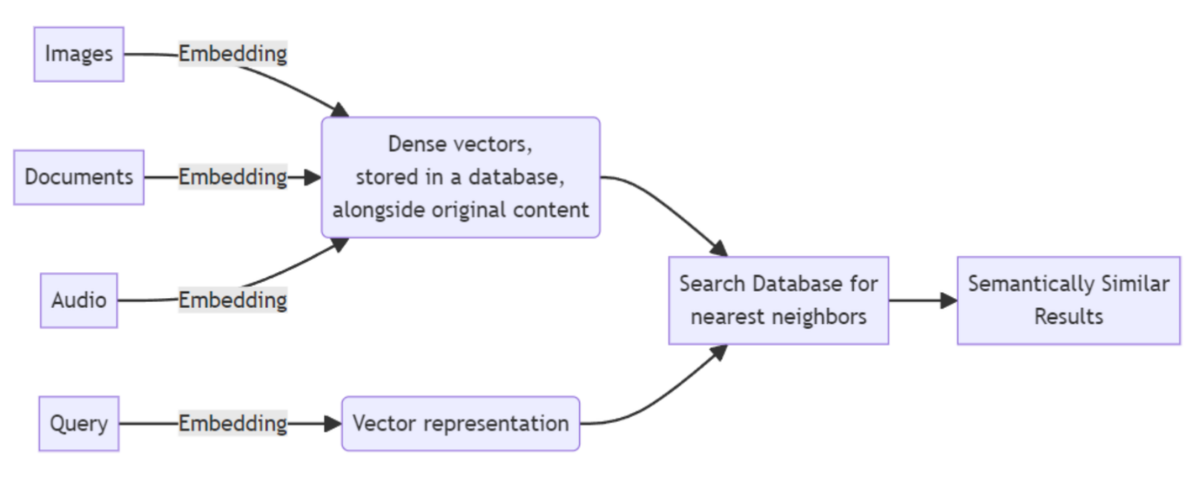
To solve this, engineers project these tokens into a massive, multi-dimensional mathematical space. Imagine a sprawling 3D grid, but instead of three dimensions, modern models use thousands of distinct mathematical axes to map semantic meaning.
-
Spatial Relationships: The token for "King" and the token for "Queen" are mathematically mapped extremely close to each other on this grid because they share similar contexts.
-
Contextual Distance: The token for "Apple" (the fruit) will be mapped far away from "Apple" (the tech company) depending on the surrounding words in your prompt.
-
Vector Mathematics: The AI can literally perform algebra on language. The classic example in data science is calculating the vector: [King] - [Man] + [Woman] = [Queen].
The machine does not know what a queen is. It simply knows exactly where that specific coordinate exists on its internal mathematical map.
You cannot learn this level of data manipulation by watching generic videos. Mastering the underlying algebra that dictates how language is stored requires rigorous, hands-on execution. Attending a dedicated training institute in Bangalore provides the massive computational resources necessary to actually visualize and manipulate these high-dimensional embeddings yourself. When you understand how the machine plots its coordinates, you can finally control exactly how it outputs its responses.
The Transformer Architecture Breakthrough
Before 2017, the entire field of natural language processing was paralyzed by a massive structural bottleneck. Engineers were forced to rely entirely on Recurrent Neural Networks to process text. These legacy systems operated under a brutal, linear constraint.
They had to read an entire paragraph sequentially, processing word number one before they could even look at word number two. If you fed the system a massive technical document, it would completely forget the first paragraph by the time it concluded. The system simply could not hold enough context in its active memory to generate coherent, long-form responses.
The introduction of the Transformer architecture completely shattered this sequential limitation.
Transformers do not read left to right. They process every single word in your prompt simultaneously. This massive parallel processing capability allows the model to instantly map the mathematical relationships between words at the beginning of a document and words at the very end.
Let us contrast the exact mechanical differences between these two architectures to understand why this leap was so revolutionary.
|
Architectural Framework |
Processing Methodology |
The Fatal Engineering Limitation |
|
Recurrent Neural Networks (RNN) |
Strict sequential processing. Reads one token at a time in absolute order. |
Severe memory decay. Fails when attempting to summarize lengthy technical documentation. |
|
The Modern Transformer Model |
Massive parallel processing. Analyzes all tokens within the context window simultaneously. |
Extremely computationally expensive. Requires thousands of advanced GPUs to execute the matrix multiplication. |
By breaking the chain of linear processing, engineers unlocked the ability to scale these models to an unprecedented size.
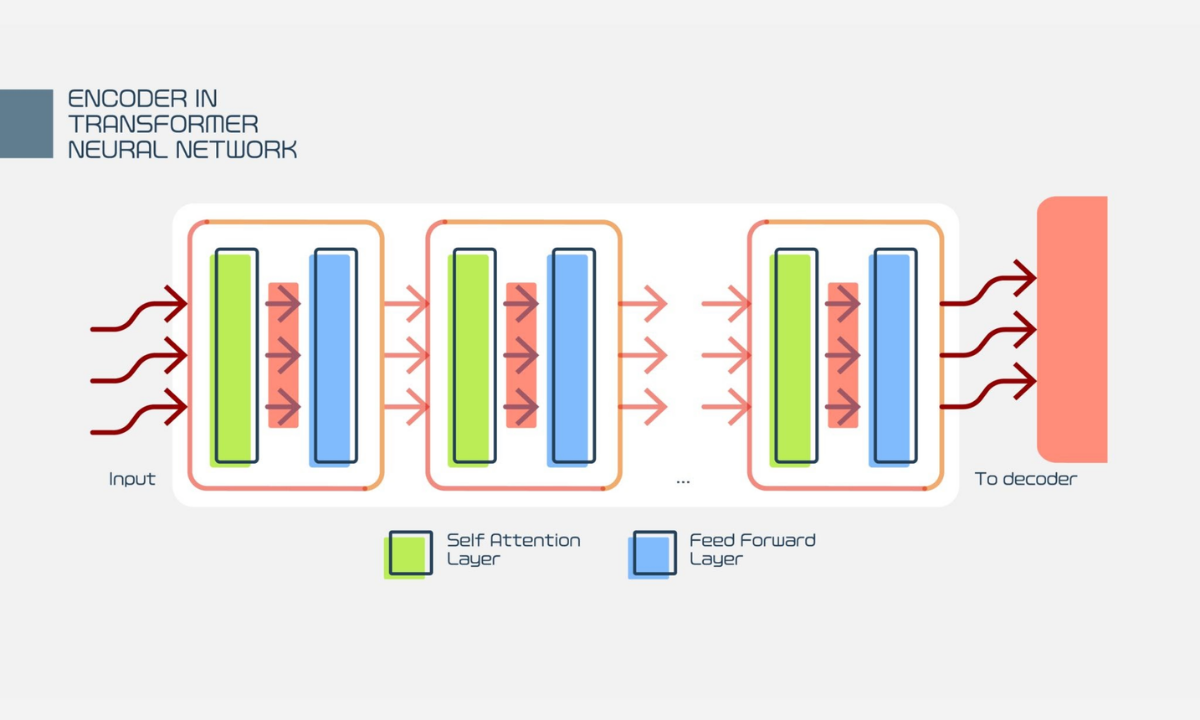
This simultaneous ingestion of data is exactly what allows modern AI to digest entire codebases or complex legal contracts in seconds. The Transformer is not just a faster reader. It is fundamentally a different mathematical engine that treats the entire text block as a single, connected web of numerical relationships.
To execute this simultaneous mapping without losing the sentence structure, the architecture relies on two highly specialized operational phases:
-
Positional Encoding: Because the model reads everything at once, it must stamp each token with a mathematical timestamp. This tells the neural network exactly where the word originally appeared in the sequence.
-
Feed-Forward Execution: Once the context is mapped, the data is pushed aggressively through massive neural networks to lock in the final predictive calculations.
This specific architectural breakthrough is the sole reason we transitioned from clunky, error-prone chatbots to the highly capable digital co-pilots dominating the 2026 tech market.
The Attention Mechanism and Deciphering Context
Mapping words to numbers is only the baseline foundation. The true engineering genius of modern artificial intelligence lies in its ability to mathematically calculate human context.
Consider the word "bank." If you feed this single word into a legacy system, it completely panics. It has absolutely no idea if you are referring to a financial institution, the side of a river, or an airplane tilting its wings. To understand the correct definition, the model must look at the surrounding words. Human professionals naturally perform this same contextual analysis when evaluating consumer search intent.
For example, understanding if a user searching for "apple" wants to buy fruit or a high-end laptop is a core psychological principle taught in any advanced digital marketing course in Bangalore.
The modern Transformer architecture does not use psychology. It uses a brutal, highly efficient mathematical operation known as the Self-Attention Mechanism.
When the model processes a sentence, it forces every single word to mathematically "attend" to every other word simultaneously. It calculates an exact relationship score between all the tokens to determine which words modify the meaning of the others. The model executes this context mapping through three incredibly specific mathematical vectors.
1. Generating the QKV Vectors
The model assigns three distinct vectors to every single word in your prompt: a Query (what context this specific word is looking for), a Key (what context this word can offer others), and a Value (the actual core semantic meaning of the word).
2. Calculating the Attention Score
To determine context, the system mathematically multiplies the Query vector of the target word against the Key vectors of every other word in the sentence. A high resulting score indicates a massive contextual relationship.
3. Applying the Softmax Filter
The raw mathematical scores are converted into strict percentages, summing to 100%. The AI now knows exactly how much mathematical "attention" the word "bank" must pay to the word "river" versus the word "money" before it generates its response.
The Multi-Head Advantage is that Enterprise models do not just perform this calculation once. They utilize "Multi-Head Attention," running dozens of these QKV calculations simultaneously. One head might focus on grammar, another on emotional tone, and another on logical sequence, combining all these perspectives into a single, flawlessly contextualized output.
This mechanism fundamentally destroyed the robotic, confused outputs of older chatbots. Because the AI mathematically weighs the importance of every word against every other word, it can easily maintain deep context across massive technical documents or complex coding queries.
The Training Pipeline and From Pre-Training to Fine-Tuning
Understanding the raw mathematical architecture is useless if you do not know how to actually train the system.
A completely raw Transformer model is dangerous. If you ask a base model how to hotwire a car, it might simply give you the exact instructions, or it might reply with a completely random Wikipedia article about cars. It has zero concept of helpfulness or safety. It only knows statistical probability.
Transforming that raw mathematical engine into a polished, production-ready digital assistant requires a massive, multi-stage engineering pipeline. The 2026 tech market strictly separates engineers who only know how to prompt from those who know how to navigate this exact pipeline.
Let us clearly define the three distinct evolutionary stages of a modern language model.
|
Model State |
The Training Data |
The Core Engineering Capability |
|
The Raw Base Model |
Trillions of raw web tokens, books, and code repositories. |
Pure next-word prediction. Highly intelligent but completely unsteerable and prone to severe hallucination. |
|
Supervised Fine-Tuning (SFT) |
Thousands of highly curated, human-written instruction and response pairs. |
The ability to follow direct commands and format outputs (e.g., "Write a Python script" instead of just completing a sentence). |
|
The Aligned Enterprise Model |
Massive datasets of human preference rankings (RLHF) or direct preference pairs (DPO). |
Deep contextual nuance, strict adherence to corporate safety guardrails, and highly structured reasoning. |
To bridge the gap between a model that simply follows instructions and a model that actually behaves like a helpful professional, engineers rely on Alignment Shaping. Before 2026, this was handled almost exclusively by Reinforcement Learning from Human Feedback (RLHF), which required building complex secondary "reward models."
Today, the industry has aggressively shifted toward streamlined, highly efficient alignment pipelines.
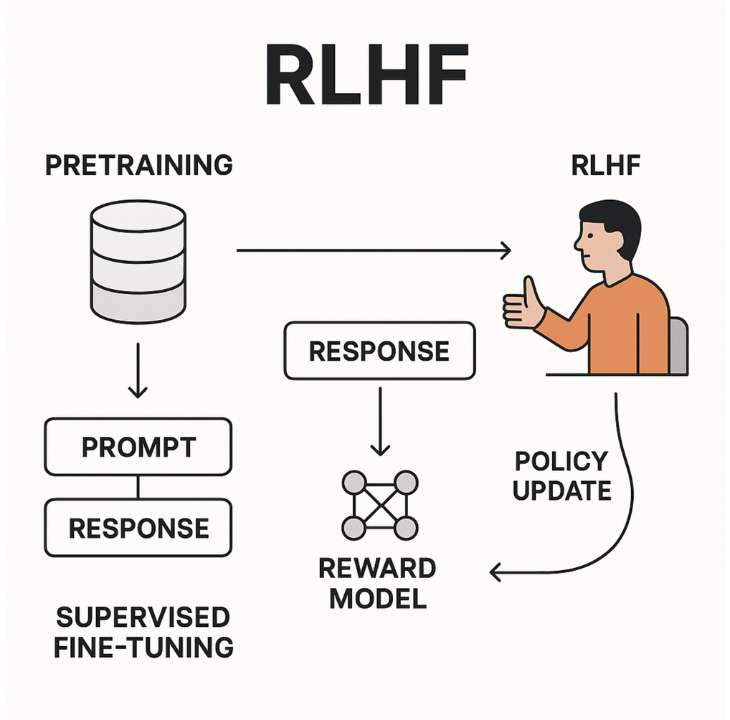
If you are building models specifically for advanced mathematics or complex coding, the 2026 pipeline increasingly utilizes Group Relative Policy Optimization (GRPO).
This bypasses human preference entirely, scoring the model automatically based on whether its generated code actually compiles and executes correctly. Mastering this pipeline, knowing exactly when to use an efficient LoRA adapter versus running a full DPO optimization is what separates a generic developer from a high-paid AI architect.
Why Choose Apponix Academy to Master AI Architecture?
Knowing how to type a clever text prompt into an interface will not protect your career in the 2026 tech economy. Automated workflows are already capable of prompting themselves. The high-paying opportunities belong exclusively to the engineers who can step behind the curtain, the ones who understand vector math, fine-tune models using DPO architectures, and securely deploy open-source models within corporate infrastructure.
Apponix Academy completely bypasses superficial AI training to focus entirely on deep, production-level model engineering.
-
Hands-On Infrastructure Access: We completely ban theoretical learning. You will actively interact with high-performance cloud compute to deploy, fine-tune, and optimize real open-source models like Llama and Mistral.
-
The 100% Placement Assurance Pipeline: Breaking into the AI engineering tier is notoriously gatekept. Our dedicated recruitment team bypasses standard resumes entirely, putting your functional portfolio directly in front of engineering directors who need immediate talent.
-
Production-Ready Portfolio Building: You will not graduate with a generic certificate. You will leave with a verified GitHub repository showcasing custom-built RAG pipelines, fine-tuned adapters, and optimized model architectures.
-
Active Practitioner Guidance: You are not taught by academic lecturers who have never deployed a model. Our mentors are active data scientists and AI architects who spend their days solving real enterprise hallucination and compute bottlenecks.
-
Rigorous Engineering Mock Interviews: Passing an AI interview requires deep algorithmic clarity. We aggressively simulate intense technical screening sessions covering everything from attention matrices to hyperparameter tuning to build absolute confidence under pressure.
We give you the precise mathematical and engineering framework required to shift from a consumer of artificial intelligence to an elite architect who builds it.
Conclusion
Large Language Models are not magical black boxes possessing human consciousness. They are massive, predictable, and highly engineerable mathematical engines. The global shift toward autonomous AI means the demand for professionals who intimately understand tokenization, transformers, and alignment pipelines is accelerating at an unprecedented velocity. Continuing to treat AI as a mysterious tool rather than a manageable piece of data infrastructure places your technical longevity at a massive disadvantage.
The strategic window to establish yourself as a foundational AI architect is open right now. You simply need the discipline to look past the interface and master the underlying code. Take control of your career path, stop relying on basic shortcuts, and start engineering the future of natural language processing today.

Apponix Academy
Apponix Academy